Ansible for Infrastructure: Lessons Learned In My Homelab Automation Efforts
If you’ve followed my recent posts, you’ll know that I’ve been on a learning journey to pick up Ansible for automating my homelab. The goal was to have one master playbook, ‘one playbook to rule them all,’ which would not only handle configuring servers and managing my services running in Docker but also manage the existence and configuration of all my Proxmox VMs. Ultimately, the task of managing VMs this way would be better suited for a tool like Terraform. But, after stumbling across the various community modules for managing Proxmox with Ansible, it seemed to have the capabilities I was looking for. So, I decided to learn one thing at a time and make my best attempt at doing everything with Ansible.
TL;DR
- My goal was to create the ability to manage changes to my homelab infrastructure, including the existence and configurations of VMs in my Proxmox cluster, by running a single playbook.
- Unfortunately, limitations to the Proxmox modules for Ansible dictated that I break this up into multiple different playbooks which would be run contextually. (If I need to delete VMs, I would run the delete playbook. If I need to modify VMs, I would run the modify playbook. Etc.)
- Ansible is still capable of interacting with Proxmox and providing homelab automation, just not in the declarative fashion that Ansible is best known for.
One playbook to rule them all
My desired end state for this master playbook was that it would do the following:
- Ensure a baseline configuration on all of my Proxmox hosts:
- Set up ssh with my ssh keys
- Install and bring up tailscale
- Set up other baseline host configurations like enabling iommu for pcie passthrough
- Ensure desired VMs exist on the cluster in a declarative fashion. Meaning that a single YAML file would declare my infrastructure. If I wanted a VM modified, I would just modify the YAML file. If I wanted a VM deleted, I would declare that in the YAML file as well.
- Ensure a baseline configuration for all VMs at the OS level (same thing as step 1 for the Proxmox hosts).
- Ensure all desired services exist and are running in Docker (in the same declarative fashion as step 2).
If all went well, this would have nearly my entire homelab defined in code. If I wanted to change something, migrate something, deploy something… simply modifying some YAML files and running the playbook would take care of everything.
Issues with parallelism
The first major obstacle I encountered was how the Proxmox modules behave in conjunction with Ansible’s parallelism. By default, Ansible will execute a task against all hosts in parallel; meaning they all execute at the same time. This is an intentional feature of Ansible and is one of the many things that makes it so efficient.
I’ll give a quick example of how parallelism can increase efficiency. Let’s say you’re copying your SSH key to a bunch of servers. If you do it with Ansible, your key will be copied to all servers at the same time, rather than waiting for one copy operation to finish before moving on to the next. (Really, the default ‘batch’ size is 5… so it will copy to 5 servers at a time. But you can modify this.)
Here’s our problem. If we have all of our Proxmox hosts in an Ansible group… and we run a playbook against that group which creates a VM on our Proxmox cluster… what’s really happening under the hood, is that we’re accessing all of our hosts in the cluster at the same time, and asking them to create the exact same VM, all at the same time. This is true of all operations against VMs in the cluster to include modifying and deleting. In testing, I noticed that sometimes the task would be successful on one host and just fail with a file lock error on the remaining hosts, but oftentimes it would be unsuccessful altogether. The image below illustrates this issue.
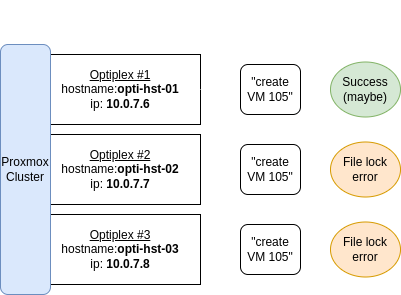
Luckily there is a workaround for this. Although not ideal, as it does increase the runtime of our playbook and can cause issues when running other tasks that should work in parallel. We can simply set the ‘batch’ size (what Ansible calls a ‘fork’) to one. We do this by adding this line at the playbook level:
serial: 1What killed my hopes and dreams
What truly ruined my plans, however, was this: the community modules for Proxmox aren’t truly declarative. To best illustrate what I mean by this, let’s take a look at the playbook I wrote to deploy VMs on my cluster. If you’re curious how I got to this point, you can check out my previous two blog posts which should (mostly) explain what’s going on here. (I’ve admittedly made several changes since that post in trying to perfect the playbook). The most current version can be found on my github.
---
- name: Deploy desired VMs on Proxmox cluster
hosts: proxmox
serial: 1
user: root
tasks:
- name: Create VMs from machines_deploy_vars.yml
throttle: 1
community.general.proxmox_kvm:
# Credentials and host/node to work from
node: "{{ item.node }}"
api_user: "{{ proxmox_username }}"
api_token_id: "{{ proxmox_token_id }}"
api_token_secret: "{{ proxmox_token_secret }}"
api_host: "{{ ansible_facts['vmbr0.7']['ipv4']['address'] }}"
# Basic VM info
vmid: "{{ item.vmid }}"
name: "{{ item.name }}"
ostype: "{{ item.ostype }}" # See https://docs.ansible.com/ansible/latest/collections/community/general/proxmox_kvm_module.html
# Hardware info
memory: "{{ item.memory }}"
cores: "{{ item.cores }}"
scsihw: virtio-scsi-pci
ide:
ide2: '{{ item.storage }}:cloudinit,format=qcow2'
serial:
serial0: socket
vga: serial0
boot: order=scsi0;ide2
## TODO - Find a way to specify number of interfaces in vars
# Storage and network info
net:
net0: 'virtio,bridge=vmbr0,tag={{ item.vlan }}'
ipconfig:
ipconfig0: 'ip={{ item.ip_address }},gw={{ item.gateway }}'
nameservers: "{{ item.nameservers }}"
# Cloud-init info
ciuser: "{{ ciuser }}"
cipassword: "{{ cipassword }}"
sshkeys: "{{ lookup('file', lookup('env','HOME') + '/.ssh/id_rsa.pub') }}"
# Desired state
state: present
ignore_errors: true
# Loop through desired machines in machines_deploy_vars.yml
loop: "{{ machines_deploy }}"
# Resize boot disk
- name: Import cloud-init disk from corresponding template
community.general.proxmox_disk:
api_user: "{{ proxmox_username }}"
api_token_id: "{{ proxmox_token_id }}"
api_token_secret: "{{ proxmox_token_secret }}"
api_host: "{{ ansible_facts['vmbr0.7']['ipv4']['address'] }}"
vmid: "{{ item.vmid }}"
disk: scsi0
size: "{{ item.disk_size }}"
storage: "{{ item.storage }}"
state: resized
- name: Import cloud init drive and power VMs on
include_tasks: machines_bootstrap.yml
loop: "{{ machines_deploy }}"
This playbook is meant to be called by a main.yml file with the import_playbook module after making the desired configurations on the Proxmox host. As you can probably tell, it loops through a variable file deploying VMs with the declared VM ID, memory, cores etc.
Now, if this behaved declaratively, we would expect that the playbook would do something like this:
- Check whether a VM with the specified name and VM ID exists in the cluster
- If it doesn’t exist, create it with the specified VM hardware
- If it does exist, check that the existing VM has the same hardware specified, and if not, modify the VM accordingly
Here’s the thing. Step 3 doesn’t happen. At least, not automatically. By adding the parameter ‘update: true’ to the playbook, the module will indeed update the VM. So why don’t we just add that parameter and call it a day? Because if we add that parameter, step 1 and 2 get skipped. The update parameter appears to preemptively assert to Ansible that the specified VM already exists. If it doesn’t actually exist, the task will simply produce an error.
Now, let’s say we got scripty with this and simply wrote our own task with the builtin shell module which runs a command to check for the existence of a VM, stores the result in a variable and then conditionally runs the Proxmox task with or without the update parameter depending on the value of that variable. That kind of logic should be unnecessary in Ansible, so it would be annoying to do so, but it could work.
Assuming we got that working, the update parameter still has significant limitations. The docs state:
"Because of the operations of the API and security reasons, I have disabled the update of the following parameters net, virtio, ide, sata, scsi. "Therefore, even if we got our crafty conditionals working (executing the update parameter only if the VM already exists), we still cannot update the VM’s network adapters or hard disks. I also found in testing that many options not listed above simply do not update with this parameter. For example, say you would like to migrate the VM to a new storage backend by updating the storage parameter. Well, that would require yet another parameter (migrate: true), which behaves very similarly to the update parameter.
Where I Landed
Now, let’s revisit what my desired end state was:
“Ensure desired VMs exist on the cluster in a declarative fashion. Meaning that a single YAML file would declare my infrastructure. If I wanted a VM modified, I would just modify the YAML file. If I wanted a VM deleted, I would declare that in the YAML file as well.”
Unfortunately, it doesn’t appear that Ansible is capable of meeting this standard when it comes to management of VMs in Proxmox. That doesn’t mean that Ansible is entirely useless in this arena though. Here’s what I ultimately ended up with:
- One variable file defines VMs that I would like to exist in the cluster.
- Another variable file defines any desired modifications to those VMs.
- A third variable file defines any VMs that I would like to delete.
- Each of these variable files have a corresponding playbook that must be called independently.
What this means, is that I’ve broken the concept of ‘one playbook to rule them all.’ When it comes to managing the VMs in my cluster, I will need to independently call the correct playbook in order to create, modify or delete any VMs.
But, all is not lost! I have still come a long way from manually deploying VMs in the Proxmox GUI. Though these playbooks aren’t as powerful as I would like them to be, they still inject a serious amount of automation into my homelab workflow.
Future Plans
The struggles along this journey have definitely caused me to look deeper into learning Terraform. On paper, Terraform is the tool for the job here. A friend of mine recently dove into using Terraform for Proxmox and unfortunately ran into some struggles with it. After some trial and error, he was able to get it working with a tutorial on the Jim’s Garage YouTube channel. It looks like updates to the Proxmox API in Proxmox 8 may be the culprit. I’m excited to dive into Terraform and see what the issues are firsthand.
Definitely check out my friend’s blog. Hopefully he’ll post some of what he’s learned about Terraform there soon!
If you’re interested in the current state of my Ansible playbooks, I keep them updated on this github repo.